
Part-of-speech (POS) tagging, a common NLP technique, refers to classifying words in a text (corpus) in accordance with a specific part of speech, depending on the word’s definition and its context.
A type of classification known as tagging is the automatic description assignment of the tokens. Here, the descriptor is referred to as a tag and it may represent a segment of speech, semantic data, and so forth. Most of the POS tagging falls under Rule Base POS tagging, Stochastic POS tagging, and Transformation-based tagging.
Rule-based POS Tagging
Rule-based taggers look up potential tags for each word in a dictionary or lexicon. Rule-based taggers employ hand-written rules to choose the correct tag when a word has more than one possible tag.
Rule-based POS tagging’s two-stage architecture also helps us grasp it.
The first stage involves assigning each word a list of potential parts of speech using a lexicon.
Second step: In the second stage, it sorts the list down to a single part-of-speech for each term using extensive lists of hand-written disambiguation criteria.

POS Tagging’s Rule-Based Properties
- These taggers are knowledge-driven taggers.
- The rules in Rule-based POS tagging are built manually.
- The information is coded in the form of rules.
- Smoothing and language modeling are defined explicitly in rule-based taggers.
Stochastic POS Tagging
Another technique of tagging is Stochastic POS Tagging. Now, the question that arises here is which model can be stochastic. The model that includes frequency or probability (statistics) can be called stochastic. Any number of different approaches to the problem of part-of-speech tagging can be referred to as stochastic taggers.
Tag Sequence Probabilities
It is another approach of stochastic tagging, where the tagger calculates the probability of a given sequence of tags occurring. It is also called the n-gram approach. It is called so because the best tag for a given word is determined by the probability at which it occurs with the n previous tags.
Properties of Stochastic POST Tagging
Stochastic POS taggers possess the following properties −
- This POS tagging is based on the probability of the tag occurring.
- It requires training corpus
- There would be no probability for the words that do not exist in the corpus.
- It uses different testing corpus (other than training corpus).
Word Frequency Approach
In this approach, the stochastic taggers disambiguate the words based on the probability that a word occurs with a particular tag. We can also say that the tag encountered most frequently with the word in the training set is the one assigned to an ambiguous instance of that word. The main issue with this approach is that it may yield an inadmissible sequence of tags.
Transformation-based Tagging
Brill tagging is another name for transformation-based tagging. It is an example of transformation-based learning (TBL), a rule-based technique for automatically labeling POS to the provided text.
It is inspired by both the rule-based and stochastic taggers that were previously explained. Rule-based and transformation taggers are similar in that they are both based on rules that indicate which tags must be applied to which words.
Working of Transformation Based Learning (TBL)
In order to understand the working and concept of transformation-based taggers, we need to understand the working of transformation-based learning. Consider the following steps to understand the working of TBL −
- Start with the solution − The TBL usually starts with some solution to the problem and works in cycles.
- Most beneficial transformation chosen − In each cycle, TBL will choose the most beneficial transformation.
- Apply to the problem − The transformation chosen in the last step will be applied to the problem.

Advantages of Transformation-based Learning (TBL)
The advantages of TBL are as follows −
- We learn a small set of simple rules and these rules are enough for tagging.
- Development as well as debugging is very easy in TBL because the learned rules are easy to understand.
- Complexity in tagging is reduced because in TBL there is an interlacing of machine-learned and human-generated rules.
- Transformation-based tagger is much faster than the Markov-model tagger.
Disadvantages of Transformation-based Learning (TBL)
The disadvantages of TBL are as follows −
- Transformation-based learning (TBL) does not provide tag probabilities.
- In TBL, the training time is very long especially on large corpora.
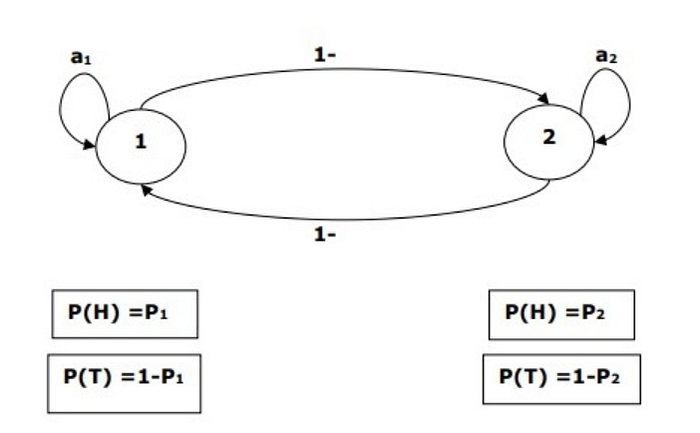
Hidden Markov Model (HMM) POS Tagging
Before digging deep into HMM POS tagging, we must understand the concept of Hidden Markov Model (HMM).
Hidden Markov Model
An HMM model may be defined as the doubly-embedded stochastic model, where the underlying stochastic process is hidden. This hidden stochastic process can only be observed through another set of stochastic processes that produces the sequence of observations.
Conclusion
In this article, we are learning about breaking the sentence into a single word. Even though a special character can split into a word. A POS tagger takes in a phrase or sentence and assigns the most probable part-of-speech tag to each word. In practice, input is often pre-processed. One common pre-processing task is to tokenize the input so that the tagger sees a sequence of words and punctuations. Other tasks such as stop word removals, punctuation removals, and lemmatization may be done before tagging.
Final Year-ET-A
Atharva Mali (30)
Avinash Gedam (32)
Akhil Bhalgat (44)
